Kafka : 스트림 처리 - (2)
💡 해당 글은 '카프카 핵심 가이드 2nd Edition'을 읽고 정리한 글입니다.

3️⃣ 스트림 처리 디자인 패턴
스트림 처리 아키텍처의 공통된 요구 사항을 잘 처리는 기본 디자인 패턴들을 살펴보자.
단일 이벤트 처리

가장 단순한 스트림 처리 패턴으로, 각각의 이벤트를 개별적으로 처리하는 것이다.
- 불필요한 이벤트를 스트림에서 걸러내거나 각 이벤트를 변환하기 위해 사용되는 경우가 많아 맵/필터(map/filter) 패턴이라고도 불린다.
- 스트림의 이벤트를 읽어와서 각각의 이벤트를 수정한 뒤, 수정된 이벤트를 다른 스트림에 쓴다.
- 위 예시는 로그 이벤트를 읽어와서 우선순위가 높은 ERROR 이벤트를 우선순위가 높은 토픽에, 나머지는 우선순위가 낮은 토픽에 쓰는 것이다.
- 각각의 이벤트가 독립적으로 처리될 수 있기 때문에, 애플리케이션 안에서 상태를 유지할 필요가 없다.
- 상태를 복구할 필요도 없기 때문에, 장애 복구나 부하 분산이 매우 쉽다.
로컬 상태와 스트림 처리

위도우 집계와 같이 정보의 집계에 초점이 맞춰져 있는 비즈니스 로직에 사용되는 패턴이다.
- 집계를 할 때는 스트림의 상태를 유지할 필요가 있기 떄문에, 상태를 각 애플리케이션의 로컬상태로 관리한다.
- 애플리케이션의 각 인스턴스는 자신에게 할당된 파티션에 쓰여진 전체 상태의 부분집합을 유지하는 것이다.
로컬 상태 사용시 고려사항
애플리케이션은 로컬 상태를 보유하게 되는 순간 훨씬 복잡해지며, 고려 사항은 다음과 같다.
✅ 메모리 사용
- 로컬 상태는 애플리케이션 인스턴스가 사용 가능한 메모리 안에 들어갈 수 있는 게 이상적이다.
- 어떤 로컬 저장소는 디스크에 내용물을 저장하는 기능을 지원하지만, 이는 성능에 상당히 영향을 미친다.
✅ 영속성 ( persistence )
- 애플리케이션 인스턴스가 종료되었을 때, 상태가 유실되지 않을 뿐더라 재실행, 대체 되었을 때 복구될 수 있음을 확신할 수 있어야 한다.
- 카프카 스트림즈는 내장된 RocksDB를 사용함으로써 로컬 상태를 데이터 영속적으로 관리 및 저장한다.
- 하지만 여기서 로컬 상태에 대한 모든 변경 사항은 카프카 토픽에도 보내진다.
- 카프카는 이러한 것들이 끝없이 자라나는 것을 방지하기 위해, 로그 압착을 사용한다.
✅ 리밸런싱
- 파티션은 서로 다른 컨슈머에게 할당될 수 있다.
- 재할당이 발생하면 파티션을 상실한 인스턴스는 마지막 상태를 저장하여 재할당받은 인스턴스가 이어서 수행할 수 있도록 해야 한다.
다단계 처리 / 리파티셔닝

그룹별 집계를 한 뒤, 사용 가능한 모든 상태 정보를 기반으로 추가적인 정보를 생성해야 할때 적용할 수 있는 패턴이다.
- 매일 상위 10개를 계신해야 한다고 가정해보면, 그룹별 집계만으로는 부족하다.
- 이때 집계한 정보를 리파티셔닝하는 새로운 토픽을 두는 단계를 추가하면 구현이 가능하다.
- 새로운 토픽의 경우, 전체 상태 내역을 포함하는 토픽에 비해 크기도 트래픽도 작기 때문에, 단일 인스턴스만 가지는 애플리케이션만으로도 충분히 처리할 수 있다.
외부 검색을 사용하는 처리 : 스트림-테이블 조인

외부 데이터를 스트림과 조인하는 패턴이다.
- 거래 내역을 데이터 베이스에 저장된 규칙을 사용해 검증하거나, 사용자 클릭 내역을 사용자 정보와 합치는 예시가 있다.
- 클릭 이벤트라면, 위 예시와 같이 이벤트 발생시 프로필 데이터베이스와 조인하여 토픽에 저장하는 것이다.
- 간단해 보이지만, 외부 검색이 각각의 레코드를 처리하는데 있어서 상당한 지연을 발생시킬 수 있다.
- 성능과 가용성을 모두 잡기 위해서는, 스트림 처리 애플리케이션 안에 데이터베이스에 저장된 데이터를 캐시할 필요가 있다.
- 하지만 데이터 베이스 변경이 자주 발생한다면 캐시 또한 관리하기 어렵다.

데이터베이스 테이블에 가해지는 모든 변경점을 이벤트 스트림에 담을 수 있다면, 캐시를 업데이트하는데 활용할 수 있다.
- 데이터 베이스의 변경 내역을 이벤트 스트림으로 받아오는 것을 CDC( change data capture )라고 한다.
- 여러 카프카 커넥트는 CDC를 수행하여 데이터베이스 테이블의 변경을 이벤트로 변환하는 기능을 가지고 있다.
- 로컬 상태를 데이터 베이스 이벤트를 활용해 캐시로 활용하면 외부 데이터 베이스를 대체할 수 있다.
테이블-테이블 조인
두 개의 테이블을 조인하는 것은 언제나 윈도우 처리되지 않은 연산이며, 작업이 실행되는 시점에서 양 테이블의 현재 상태를 조인한다.
- 카프카 스트림에서는 파티션된 동일한 키를 가지는 두개의 테이블에 대해 동등 조인을 수행할 수 있다.
카프카 스트림즈는 두 개의 테이블에 대해 외래 키 조인을 지원한다.
- 한 스트림 혹은 테이블의 키와 다른 스트림 혹은 테이블의 임의 필드를 조인할 수 있는 것이다.
스트리밍 조인 / 윈도우 조인

두 개의 스트림을 조인할 경우 한쪽 스트림에 포함된 이벤트를 같은 키값과 함께 같은 시간 윈도우에 발생한 다른 쪽 스트림 이벤트와 맞춰야 하기 때문에, 과거와 현재 이벤트 전체를 조인하게된다.
- 카프카 스트림즈는 조인할 두 스트림이 똑같이 조인 키에 대해 파티셔닝 되어있을 경우, 동등 조인을 지원한다.
- 두개의 스트림이 동일한 번호의 파티션에 저장되었을 때, 카프카 스트림즈는 해당 파티션에 대한 작업을 같은 테스크에 할당한다.
- 따라서 해다 테스크는 동일한 번호의 파티션에 저장하는 이벤트를 모두 볼 수 있다.
비순차 이벤트

잘못된 시간에 스트림에 도착한 이벤트(비순차 이벤트)를 처리하는 것은 어려운 일이다.
- 예를들어 WiFi 신호가 끊긴 모바일 장치는 재접속시 몇 시간치 이벤트를 한번에 전송한다.
스트림 애플리케이션은 이러한 상황을 처리할 수 있어야 하며, 아래와 같은 일을 수행할 수 있어야 하는 것을 의미한다.
- 이벤트가 순서를 벗어났음을 알아차릴 수 있어야 한다. 이를 위해서는 이벤트 시간과 현재 시간을 비교할 필요가 있다.
- 비순차 이벤트의 순서를 복구할 수 있는 시간 영역을 정의한다.
- 순서를 복구하기 위해 이벤트를 묶을 수 있어야 한다. 배치와 달리 스트림은 늦게 도착한 이벤트를 위해 했던 작업을 되돌려 다시 계산하는 로직은 없다. 계속해서 동작하는 프로세스가 주어진 시점 기준으로 오래된 이벤트와 새로운 이벤트를 모두 처리해야 한다.
- 결과를 변경할 수 있어야 한다.
구글 데이터플로나 카프카 스트림과 같은 스트림 처리 프리임워크는 처리 시간과 독립적인 이벤트 시간의 개념을 자체적으로 지원한다.
- 현재 처리 시간 이전 혹은 이후의 이벤트 시간을 가지는 이벤트를 다룰 수 있는 기능 역시 지원한다.
- 로컬 상태에 다수의 집계 윈도우를 변경 가능한 형태로 유지해주고, 개발자가 이러한 로컬 상태를 오래 유지하도록 설정하는 식으로 구현한다.
- 하지만 이는 로컬 상태를 유지하기 위한 메모리 역시 필요하다.
카프카 스트림즈 API는 언제나 집계 결과를 결과 토픽에 쓴다.
- 이 토픽들은 대체로 로그 압착이 설정되어 있는 토픽이며, 즉 키 값에 대해 마지막 밸류값만 유지된다.
- 집계 윈도우의 결과가 늦게 도착한 이벤트로 인해 변경되어야 하는 경우, 단순히 해당 집계 윈도우의 새로운 결과값을 씀으로써 기존 결과값을 대체한다.
재처리하기
재처리를 해야 하는 경우는 아래와 같이 2가지 케이스가 있고 그에 따른해결 방법을 알아보자.
1️⃣ 새로 개선된 버전의 스트림 처리 애플리케이션이 등장한 상황에서, 기존 구버전의 결과를 교체하는 것이 아니라 한동안 두 버전의 결과를 비교한 뒤 어느 시점에 구버전 대신 신버전의 결과를 사용하도록 한다.
- 카프카는 확장 가능한 데이터 저장소에 이벤트 스트림을 오랫동안 온전히 저장하기 때문에 이는 쉽다.
- 하나의 스트림 처리 어플리케이션의 두 버전이 동시에 두 개의 결과 스트림을 쓰게하면 된다.
- 신버전 애플리케이션을 새로운 컨슈머 그룹에서 실행시키고, 입력 토픽의 첫 번째 오프셋 부터 처리하도록 설정하여 입력 스트림의 모든 이벤트에 대한 복사본을 가질 수 있도록 한다.
- 신버전 처리 작업이 따라 잡았을 때 클라이언트 애플리케이션을 새로운 결과 스트림으로 전환한다.
2️⃣ 기존의 스트림 처리 어플리케이션에 버그가 많으니 버그를 고친 뒤 이벤트 스트림을 재처리해서 결과를 다시 산출하고자 한다.
- [첫번째 방식] 이미 존재하는 애플리케이션을 초기화해서 입력 스트림의 맨 처음부터 다시 처리하도록 해야 하고, 기존 로컬 상태와 기존 출력 스트림 내용물 역시 지워야 한다.
- [두번째 방식] 카프카 스트림즈가 초기화 하는 툴을 제공한다.
- 2개 이상의 버전을 동시에 사용할 수 있고, 버전 간의 결과물을 비교할 수 있으며, 유실에 대한 걱정도 없기 때문에 첫번째 방식이 더 안전하고 권장된다.
인터랙티브 쿼리 ( interactive query )
스트림 처리 애플리케이션은 상태를 보유하며, 이 상태는 애플리케이션의 여러 인스턴스 사이에 분산될 수 있다.
- 보통 스트림 처리 애플리케이션의 사용자는 결과 토픽을 읽어드림으로써 처리 결과를 볼 수 있다.
- 하지만 상태 저장소 그 자체에서 바로 결과를 읽어올 필요는 없다.
- 처리 결과가 보통 테이블 형태인 경우가 흔하며, 이 경우 결과 스트림은 곧 이 테이블에 대한 업데이트 스트림이다.
- 이 경우 스트림 처리 애플리케이션의 상태에서 테이블을 바로 읽어오는 것이 빠르고 쉽다.
인터랙티브 쿼리(interactive query)란, 스트림 처리 애플리케이션의 상태를 유연하게 가져오기 위해 카프카에서 제공하는 API이다.
4️⃣ 카프카 스트림즈: 아키텍처 개요
토폴로지 생성하기

모든 스트림즈 애플리케이션은 하나의 토폴로지를 구현하고 실행한다.
- 유향 비순환 그래프라고도 불리며, 모든 이벤트가 입력에서 출력으로 이동하는 동안 수행되는 작업과 변환 처리의 집합을 말한다.
- 소스 프로세서(source processor)는 토픽으로부터 데이터를 읽어와서 넘겨주는 역할을 한다.
- 싱크 프로세서(sink processor)는 앞 프로세서로부터 데이터를 넘겨 받아서 토픽에 쓰는 역할을 한다.
- 토폴로지는 항상 하나 이상의 소스 프로세서로 시작해서 한 개 이상의 싱크 프로세서로 끝난다.
토폴로지 최적화하기
기본적으로 카프카 스트림즈는 DSL API를 사용해서 개발된 애플리케이션의 각 DSL 메서드를 독립적으로 저수준 API로 변환하여 실행한다. 각각의 DSL 메서드를 독립적으로 변환하기 때문에 결과 토폴로지는 전체적으로 그리 최적화되지 않은 상태일 수 있다.
카프카 스트림즈 애플리케이션은 아래와 같은 단계로 실행된다.
- KStream, KTable 객체를 생성하고 여기에 필터, 조인과 같은 DSL 작업을 수행함으로써 논리적 토폴로지를 정의한다.
- StreamBuilder.build() 메서드가 논리적 토폴로지로부터 물리적 토폴리지를 생성한다.
- KafkaStreams.start()가 토폴로지를 실행시킨다.
논리적 토폴리에서 물리적 토폴로지가 생성되는 두 번째 단계에서 토폴로지 최적화가 적용된다.
- 현재 시점에서 아파치 카프카는 몇 개의 최적화 방식을 포함하고 있을 뿐이다.
- `StreamConfig.TOPOLOGY_OPTIMIZATION`을 `StreamConfig.OPTIMIZE`로 잡아주면 활성화 할수 있다.
KStream 🆚 KTable
KStream 이미지

- 레코드의 흐름을 표현한 것으로 메세지 키와 값으로 구성되어있다.
- 조회시, 토픽에 존재하는 모든 레코드를 반환하며, 컨슈머로 토픽을 구독하는 것과 동일하다.
KTable 이미지

- KStream과 달리 메세지 키를 기준으로 묶어서 사용한다.
- 유니크한 메세지 키를 기준으로 가장 최신 레코드를 사용한다.
- 따라서 데이터 조회 시 메시지 키 기준으로 가장 최신에 추가된 레코드의 데이터가 출력된다.
- 1개의 파티션은 1개의 태스크에 할당되어 사용된다.
토폴로지 테스트하기
카프카 스트림즈 애플리케이션에서의 주된 테스트 툴은 `TopologyTestDriver`이다.
- 일반적인 단위 테스트와 동일하게, 입력 데이터를 정의하고, 목업을 설정한 후 테스트 드라이버를 써서 토폴로지를 검증한다.
- 스트림 처리 애플리케이션을 테스트하는 것에도 TopologyTestDriver를 사용할 수 있지만, 캐시 기능을 시뮬레이션 해주지 않아 찾을 수 없는 에러도 많다.
단위 테스트는 통합 테스트로 보강되는 것이 보통이다.
- 카프카 스트림즈의 경우 `EmbeddedKafkaCluster`와 `Testcontainers`의 두 통합 테스트 프레임워크를 주로 사용한다.
- EmbeddedKafkaCluster의 경우 JVM 상에 카프카 브로커를 하나 띄워주는 방식이다.
- Testcontainers는 도커 컨테이너를 사용해서 카프카 브로커와 기타 테스트에 필요한 다른 요소들을 띄워주는 방식이다.
- 도커를 사용하면 애플리케이션과 카프카를 완전히 서로 격리시킬 수 있기 때문에 후자를 권장한다.
토폴로지 규모 확장하기
스트림즈는 하나의 애플리케이션 인스턴스 안에 다수의 스레드가 실행될 수 있게 함으로써 규모 확장과 서로 다른 애플리케이션 인스턴스 간에 부하 분산이 이루어지도록 한다.

카프카 스트림즈 엔진은 토폴로지의 실행을 다수의 테스크로 분할함으로써 병렬 처리한다.
- 엔진은 애플리케이션이 처리하는 토픽의 파티션 수에 따라 테스크 수가 정해진다.
- 이벤트를 읽어 올 때마다 테스크는 이 파티션에 적용될 모든 처리 단계를 실행시킨 후 결과를 싱크에 쓴다.
- 이러한 테스크들은 서로 완전히 독립적으로 실행될 수 있기 때문에 병렬 처리의 기본 단위가 된다.
개발자는 애플리케이션 인스턴스가 실행시킬 스레드의 수를 결정할 수 있다.
- 처리하는 토픽의 파티션 수만큼 테스크를 생성하는 것, 이것이 스트리밍 애플리케이션이 규모를 확장하는 방식이다.
- 더 빨리 처리하고 싶다면 스레드 수를 늘리면 되고, 서버 자원이 고갈되었다면 인스턴스를 더 띄우면된다.
- 각각의 테스크에 파티션을 나눠서 할당해주면, 독립적으로 이벤트를 받아와 처리하고 토폴로지에 정의된 집계 연산에 관련된 로컬 상태를 유지한다.
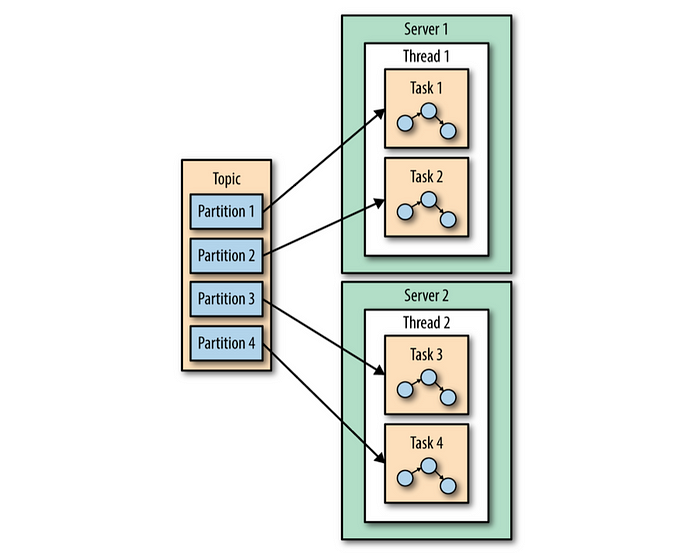
다수의 파티션에서 입력을 가져와 처리해야 할 때도 있는데, 이 경우 테스크 사이에 의존관계가 생길 수 있다.
- 클릭 스트림 예제처럼 두 스트림을 조인한다고 할 때, 결과를 내놓기 위해 각 파티션의 파티션으로부터 데이터를 읽어와야 한다.
- 스트림즈는 각각의 조인 작업에 필요한 모든 파티션들을 하나의 테스크에 할당함으로써, 독립적으로 조인을 수행할 수 있도록 지원한다.
- 조인 작업에 사용될 모든 토픽에 대해 동일한 조인 키로 파티션된 동일한 수의 파티션을 가지는 것을 요구하는 이유이기도 하다.

리파티셔닝을 해야하는 상황에서도 적용할 수 있다.
- 카프타 스트림즈는 리파티션이 호출되면 새로운 키와 파티션을 가지고 새로운 토픽에 이벤트를 쓴다.
- 그 다음에 오는 테스크들은 새 토픽에 이벤트를 읽어와서 처리를 계속한다.
- 즉, 리파티셔닝은 전체 토폴로지를 2개의 서브 토폴로지로 분할한다.
- 첫 번째 태스크 집합은 자기 속도대로 데이터를 토픽에 쓰고, 두 번째 테스크 집합 역시 자기 속도대로 처리하면 되기 때문에 여전히 독립적이고 병렬로 실행된다.
장애처리하기
카프카는 매우 가용성이 높은 시스템이며, 카프카에 저장하는 데이터 역시 마찬가지이다.
- 장애가 발생해 재시작이 필요한 경우, 장애가 발생하기 전 마지막으로 커밋된 오프셋을 카프카에서 가져옴으로써 처리하던 스트림의 마지막으로 처리된 지점부터 재개할 수 있다.
- 로컬 상태 저장소가 유실되었을 경우, 스트림즈 어플리케이션은 카프카로부터 체인지로그를 읽어옴으로써 로컬 상태 저장소를 복구한다.
카프카 스트림즈는 테스크 고가용성을 지원하기 위해 카프카의 컨슈머 코디네이션 기능을 지원한다.
- 만약 테스크에 장애가 발생했지만 다른 스레드 혹은 인스턴스가 멀쩡히 작동 중일 경우, 해당 테스크는 사용 가능한 다른 스레드에서 재시작한다.
하지만 중요하게 봐야할 것은 복구 속도이다.
- 장애가 발생한 스레드에서 실행되고 있던 테스크를 다른 스레드가 넘겨받아 처리 시작해야 할때, 가장 먼저 할 일은 저장된 상태를 복구시키는 것이다.
- 저장된 내부 토픽을 다시 읽어와서 상태 저장소를 업데이트 하는 식으로 복구할 수 있지만, 그만큼 가용성은 줄어든다.
따라서, 복구 시간을 줄이는 문제는 곧 상태를 복구시키는 데 걸리는 시간을 줄이는 것과 같다.
- 가장 핵심적인 방법은 카프카 스트림즈 토픽에 매우 강력한 압착을 설정하는 것이다.
- compaction.lag.ms는 낮추고 세그먼트 크기도 낮춤으로써 구현할 수 있다.
더 빠른 장애 복구를 위해, 우리는 스탠바이 레플리카(Standby Replica)를 설정할 것을 권한다.
- 스탠바이 레플리카란 현재 작동 중인 테스크를 단순히 따라가기만 하는 테크로서, 다른 서버에서 현재 상태를 유지하는 역할을 한다.
- 장애 발생시, 중단 시간 없이 거의 바로 처리를 재개할 수 있다.
카프카 스트림즈에서의 규모 확장성과 고가용성에 대하여
Run a Kafka Streams Application in Confluent Platform | Confluent Documentation
Kafka Streams makes your stream processing applications elastic and scalable. You can add and remove processing capacity dynamically during application runtime without any downtime or data loss. This makes your applications resilient in the face of failure
docs.confluent.io